
Why Postgres is the last database you'll need ?
Postgres can handle cache, queues, full-text search, pub/sub and vector workloads out of the box.

Every few months someone on the team opens a Slack thread with "should we add Redis?" or "do we really need Kafka for this?" The answer is usually the same. Not yet. Possibly never.
I have been running Postgres in production for a while now. Over the years I have watched it quietly absorb features that people used to stand up entirely separate services for. At some point you stop thinking of Postgres as "the relational database" and start thinking of it as the default place data goes. Everything else has to earn its spot on the architecture diagram.
This is a short tour of what a single Postgres instance can do before you start adding other boxes to that diagram.
It is a relational database. That is the boring part.
ACID transactions, foreign keys, joins, row level security, materialised views, window functions, CTEs, declarative partitioning. You already know this part. MVCC means readers don't block writers and writers don't block readers. The planner is mature. Decades of production hardening sit behind it. None of this is new.
What people miss is that the same engine running your OLTP workload is also good enough to replace three or four other services in most applications.
A cache that you already have
For session data, rate limit counters, or computed results that are annoying to regenerate, an UNLOGGED table gets you most of the way there.
CREATE UNLOGGED TABLE cache_entries (
key TEXT PRIMARY KEY,
value JSONB NOT NULL,
expires_at TIMESTAMPTZ
);
UNLOGGED tells Postgres to skip the WAL for this table. Writes are faster because nothing is being streamed to the write-ahead log, and there is no replication overhead. The tradeoff is that the table is truncated on crash recovery. For a cache, that is acceptable behaviour. It is a cache only. It is supposed to be refillable.
The write path tells the story:
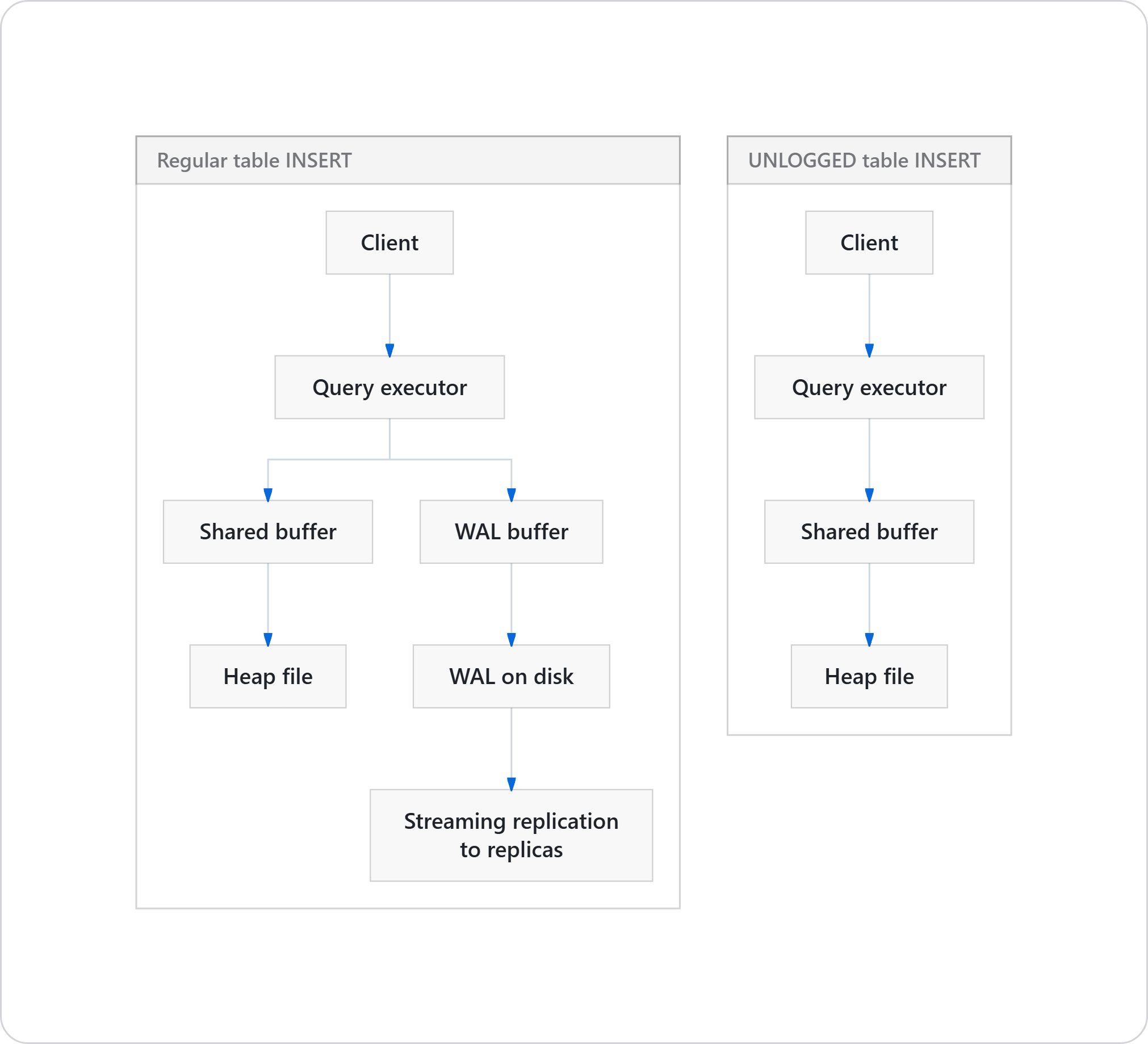
Fewer fsyncs, no WAL record, no network traffic to replicas. On a write-heavy cache workload, this is where the speed comes from.
You will not beat Redis on sub-millisecond hot path work. If you are running a real-time bidding system or a game leaderboard with thousands of concurrent updates per key, keep Redis. For most web applications where the user cannot tell the difference between 2 ms and 5 ms, an unlogged table works fine and you have one less daemon to operate.
A job queue, without the broker
SELECT ... FOR UPDATE SKIP LOCKED turns a regular table into a proper worker queue.
UPDATE job_queue SET status = 'processing', started_at = NOW()
WHERE id = (
SELECT id FROM job_queue
WHERE status = 'pending'
ORDER BY created_at
LIMIT 1
FOR UPDATE SKIP LOCKED
)
RETURNING *;
Each worker locks exactly one row. Other workers see the lock, skip it, and take the next available row. No duplicate delivery. If a worker crashes mid-job, the transaction rolls back and the row goes back into the pool on its own.
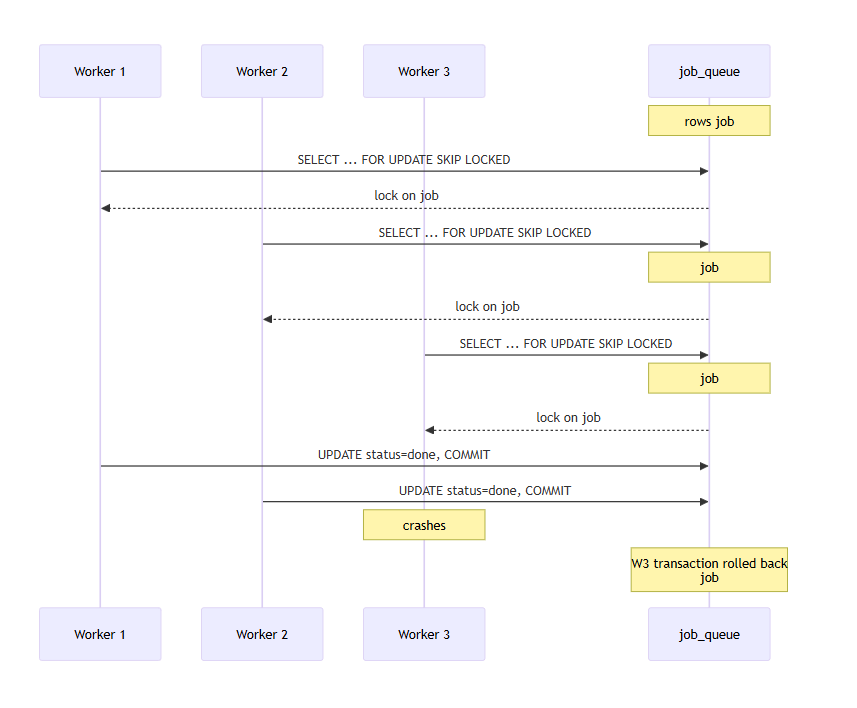
Pair it with a partial index on WHERE status = 'pending' and the index stays small forever, even after you have processed ten million jobs. The completed rows drop out of the index as their status changes.
pg-boss in Node, river in Go, Solid Queue in Rails, all of them are built on this exact pattern. If your job volume is under a few thousand per second, you do not need RabbitMQ. A table and a partial index will do.
Full-text search, properly indexed
If you have written WHERE title ILIKE '%something%' on a production table, you know how this ends. A leading wildcard forces a sequential scan, and sequential scans get slower as the table grows.
tsvector and GIN indexes solve this properly.
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
body TEXT NOT NULL,
search_vector tsvector
);
CREATE INDEX idx_articles_search ON articles USING GIN (search_vector);
The difference at the planner level is stark:
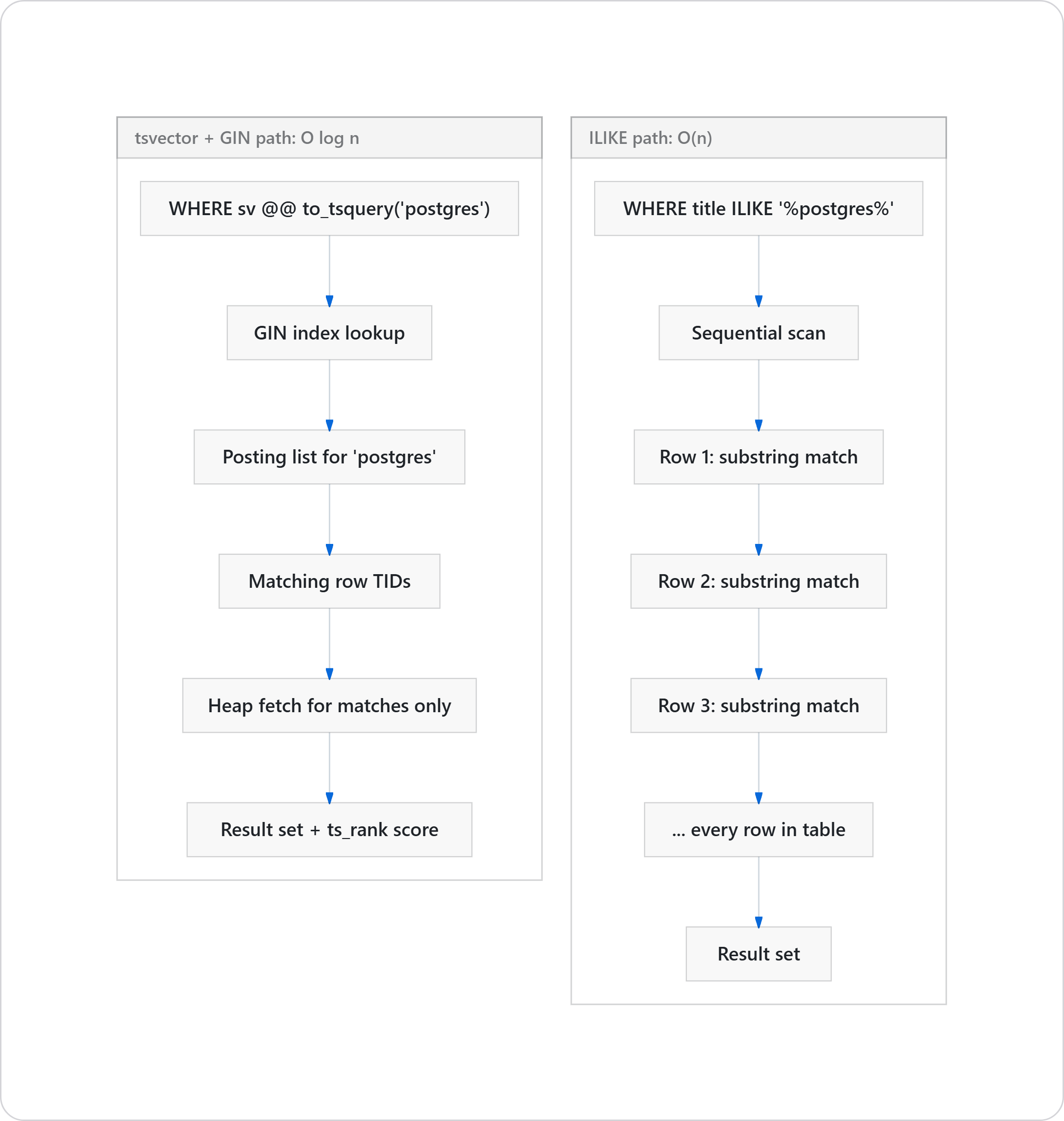
You also get stemming, stop-word removal, ranking with ts_rank, phrase search, prefix matching, weighted fields. All of it in core. No extension required. If you need more, pg_trgm adds trigram similarity for typo-tolerant search, and pgvector handles semantic search through embeddings.
For a product catalog, blog search, or an internal admin tool, this is enough. You probably do not need Elasticsearch until well past the first million documents.
Pub/sub without another daemon
LISTEN/NOTIFY has been in Postgres for a long time and most people have not touched it.
-- subscriber side
LISTEN new_order;
-- publisher side, from another session or a trigger
SELECT pg_notify('new_order', '{"id": 42, "amount": 1500}');
Drop a trigger on INSERT that calls pg_notify, and every new row fans out to whoever is listening.
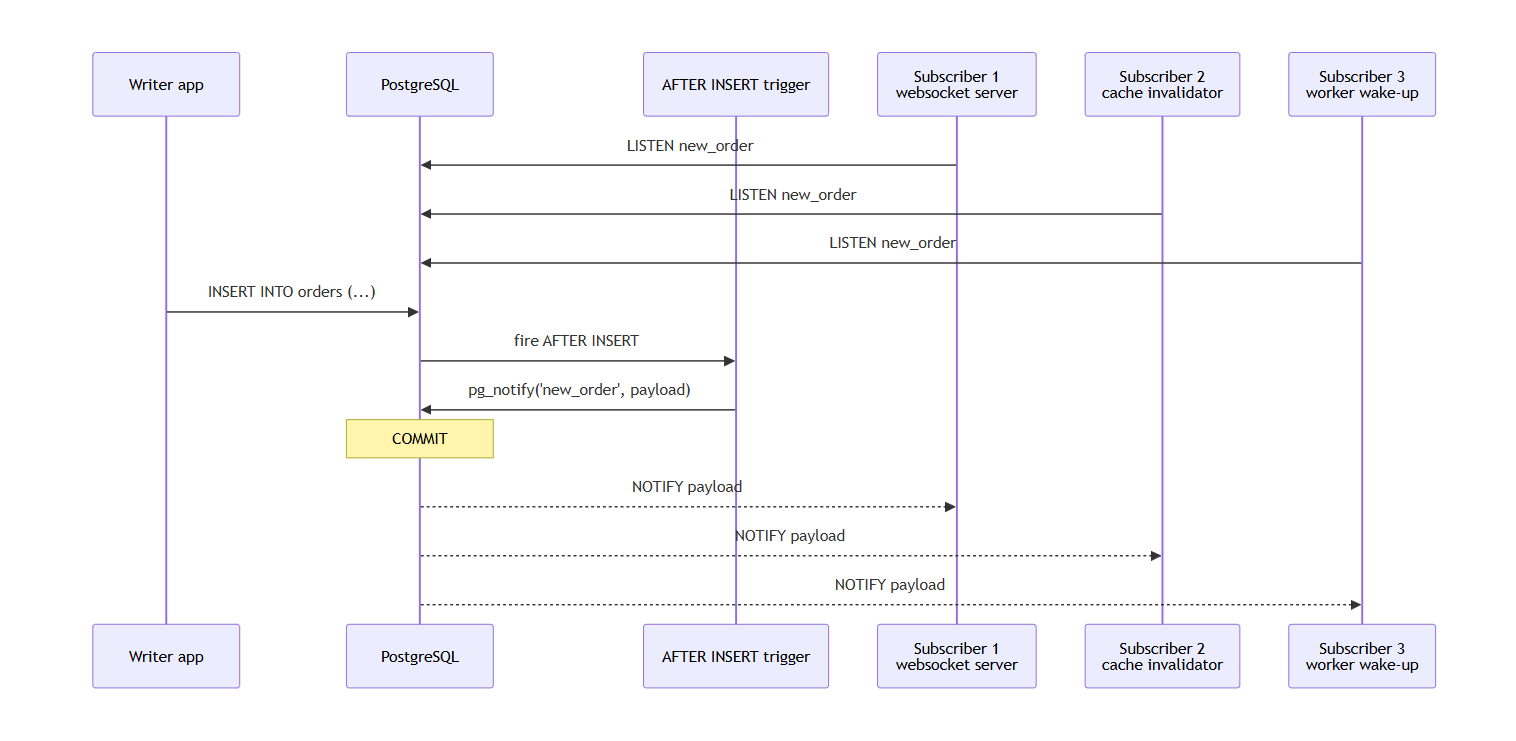
Works for real-time dashboards, cache invalidation, websocket fan-out, and background worker wake-ups.
The caveats are real. Payload limit is 8000 bytes. It does not play well with PgBouncer in transaction pooling mode because connection affinity breaks. Messages are not persisted, so if nobody is listening when NOTIFY fires, the message is gone. For what it is, it solves a real problem without adding infrastructure.
JSONB, for when your schema is not ready
Sometimes you have genuinely unstructured data. Webhook payloads from vendors who change their schema on a whim. Feature flags. User preferences. Audit logs where each event type has different fields.
JSONB gives you document storage inside your relational database. You can index individual keys with GIN, query with ->, ->>, @>, jsonb_path_query. You can enforce partial schema through check constraints where it matters, and leave the rest flexible.
This is not a reason to stop using proper columns when you know the schema. It is a reason to stop running MongoDB next to Postgres for one table full of half-known JSON.
Extensions
Core Postgres is already doing a lot. Then you have the extension ecosystem.
pgvectorfor vector similarity search with HNSW and IVFFlat indexes. RAG pipelines, recommendation engines, semantic search.TimescaleDBturns Postgres into a proper time-series database with hypertables, native compression, and continuous aggregates. Metrics, IoT telemetry, financial ticks.PostGISis still the gold standard for geospatial. Not "good enough", actually best in class.pg_cronschedules jobs inside the database itself. No separate cron container, no Kubernetes CronJob object. A row in a table that says "run this SQL every five minutes".pg_partmanautomates partition creation and retention for time-based tables.pg_stat_statementsandauto_explainare how you figure out what is slow in production. If you are not using these, you are flying blind.- Foreign Data Wrappers let you query other Postgres instances, MySQL, MongoDB, even a CSV file, as if they were local tables.
Extensions are first class citizens. CREATE EXTENSION pgvector; and you are done. No separate service, no separate wire protocol, no separate auth model.
Who actually runs on Postgres
You do not have to take this on faith. Some of the largest workloads on the internet run on Postgres, and the engineering teams have written publicly about how.
OpenAI
OpenAI runs ChatGPT and the API platform for roughly 800 million users on a single-primary Postgres instance on Azure, backed by close to 50 read replicas spread across regions. Millions of queries per second, p99 latency in the low double-digit milliseconds. They did not shard the primary, they tuned and optimised aggressively.
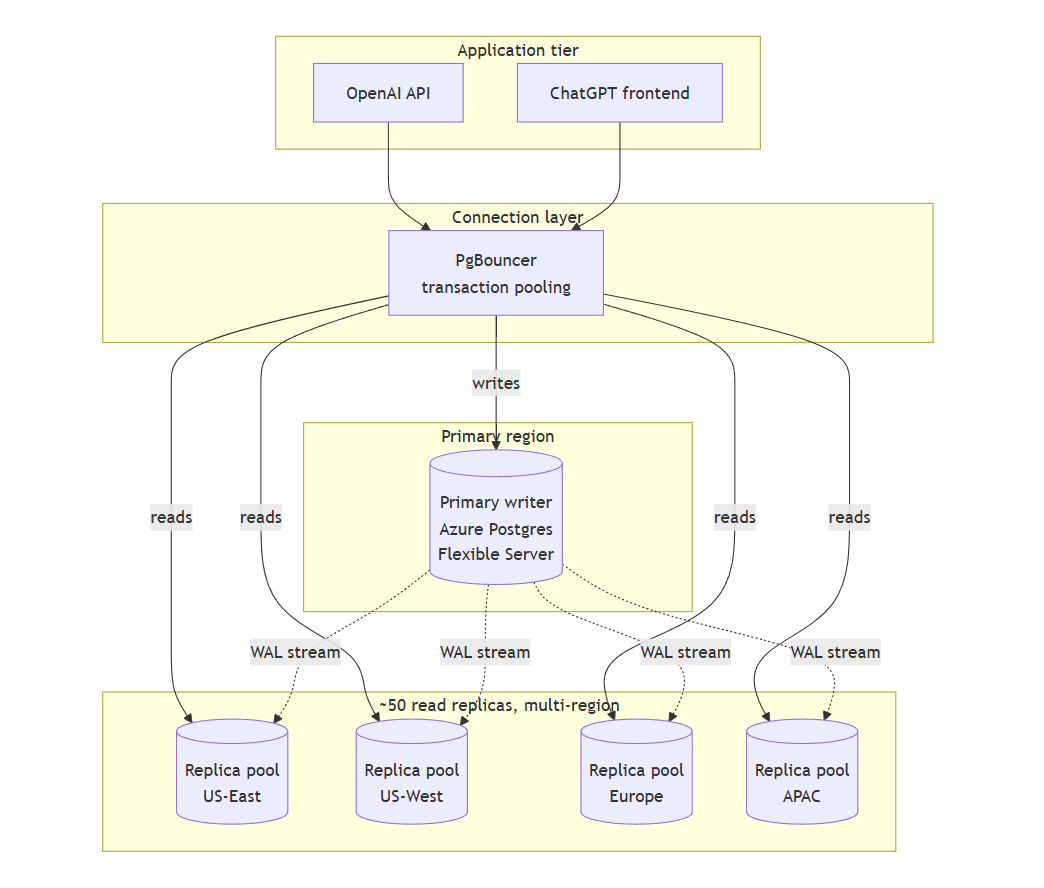
Their engineering writeup: https://openai.com/index/scaling-postgresql/

Notion
Notion stores roughly 200 billion blocks across 480 logical shards on 96 physical Postgres instances. Every page, every block, every comment is a relatively simple Postgres row, replicated across shards with application-level routing keyed on workspace_id.
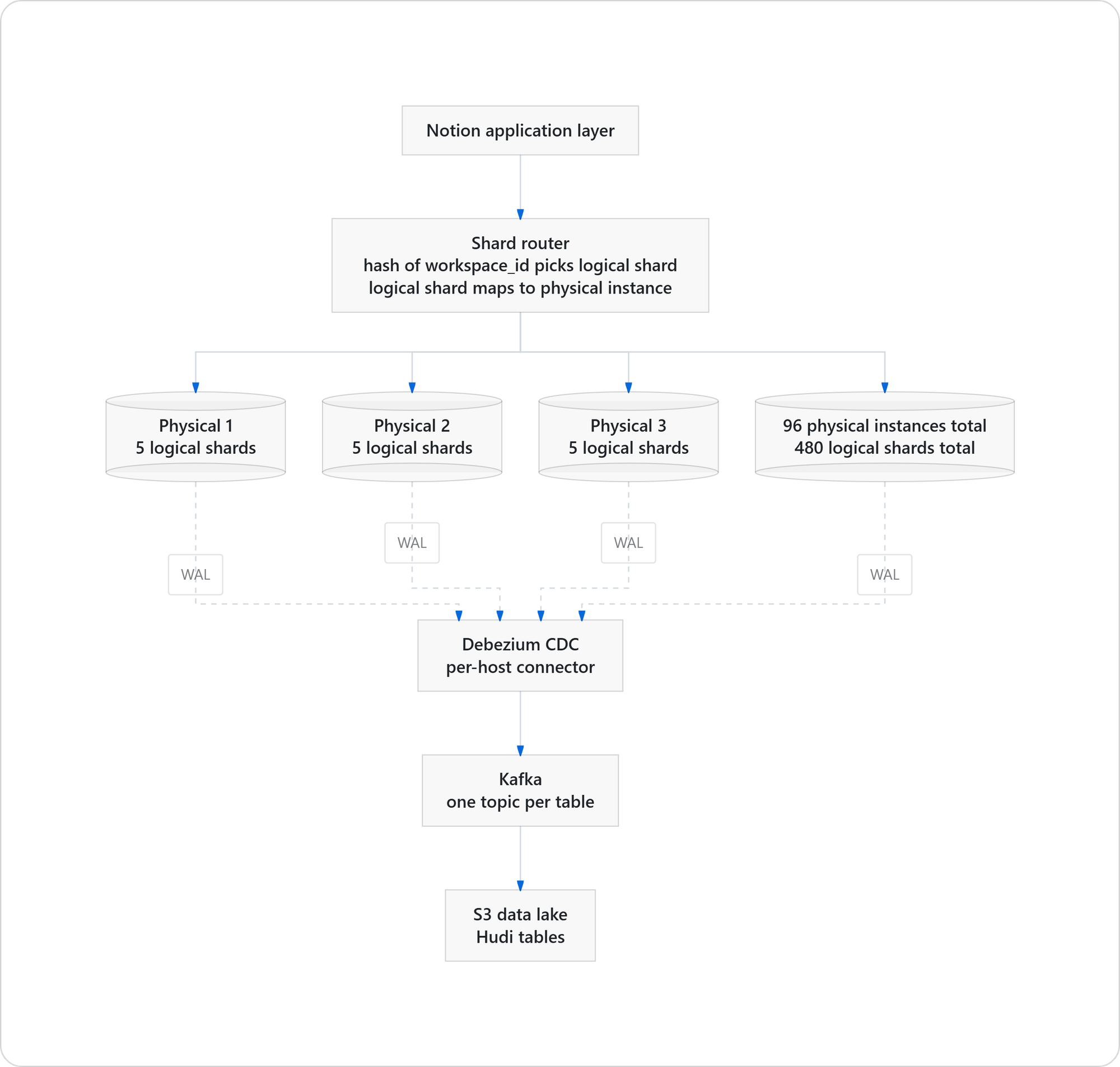
Their "Herding Elephants" post covers the original 2021 shard & The follow-up on adding capacity with zero downtime:
Figma
Figma went the other direction from Notion and did vertical partitioning, splitting tables across servers rather than sharding rows across instances. Different approach, same underlying database.
Instagram has run on Postgres since before the Facebook acquisition and publicly stayed with it through hundreds of millions of users. Their early engineering posts on scaling Postgres are still referenced in sharding discussions today.
Others worth knowing about
GitLab runs on Postgres. Heroku's own control plane does. Reddit has used it for core metadata for years. A long tail of fintechs, SaaS companies, and government systems sit on Postgres and do not talk about it publicly.
The common thread across these stories is the same. They hit scaling limits, they optimised, they sharded or partitioned when they had to, but they did not abandon Postgres. The engineering effort to scale it turned out to be meaningfully less than the engineering effort to migrate off it.
The part nobody talks about - you own your data
Every managed cloud database is also a vendor lock-in story. DynamoDB data lives inside AWS. Firestore is GCP only. Cosmos DB belongs to Azure. Moving off any of them is a migration project, not a config change.
Postgres is open source under a permissive license. Your data sits in a format a hundred tools can read. You can run it on RDS, Aurora, Cloud SQL, Azure Database, Neon, Supabase, Crunchy Data, or your own Ubuntu box in a rack. The wire protocol is the same. The dump format is the same. pg_dump from one provider, pg_restore to another, a weekend of work rather than a quarter.
This matters when pricing changes. When a provider has an outage pattern you cannot tolerate. When compliance requirements shift and data has to sit inside the country. When you simply want to leave. Optionality is a feature and very few databases actually give it to you.
Where you genuinely should stop
Postgres does not do everything, and pretending otherwise is how teams end up with production incidents.
- Sub-millisecond cache hits at a million QPS, you want Redis or Memcached.
- Millions of messages per second with durable fan-out, consumer groups, and replay semantics, you want Kafka.
- Distributed search across terabytes with complex CJK analyzers and deep faceted aggregations, you want Elasticsearch or OpenSearch.
- Petabyte-scale analytical scans, you want ClickHouse, Druid, or a proper warehouse like Snowflake or BigQuery.
These tools exist because the problems they solve are real. If you hit those walls, your benchmarks will tell you which workload is the actual bottleneck.
In simple words...
Start with Postgres. One database to back up, one to monitor, one connection pooler to tune, one replication topology, one set of alerts in Grafana, one thing to patch when the next CVE drops. When Postgres starts hurting on a specific workload, and only then, extract that workload into a dedicated service. By that point you will have production metrics that tell you exactly why, which is a much better place to be than guessing on day one.