
The Userspace Tax Behind Protocols - QUIC(UDP) vs TCP
QUIC and TCP are not interchangeable.

When you're building a service that requires inter-node communication, one of the earliest decisions is choosing a transport protocol. Nodes need to talk to each other reliably, consistently, and fast. That means picking a foundation to build on.
At the transport layer, there are really only two foundations: TCP and UDP. Everything else is built on top of one of these two. On top of TCP, we have protocols battle-tested in production for years — HTTPS, gRPC, WebSocket, and other custom protocols. These inherit TCP's reliability, ordering, and congestion control for free because TCP handles all of that at the kernel level. On top of UDP, the most prominent protocol today is QUIC. Designed by Google, standardized as RFC 9000, and powering HTTP/3, QUIC is the one that keeps coming up when teams discuss transport choices.
So when a team needs to decide how their cluster nodes communicate internally, the conversation often lands on: should we use something over TCP, or should we use QUIC over UDP? And this is where the misconception begins.
The misconception
QUIC sounds like a strong candidate. It is modern. It has built-in encryption. It solves head-of-line blocking. Google uses it. HTTP/3 runs on it. It is, by most accounts, a well-engineered protocol.
Push back with TCP, and the rebuttal is almost always: "gRPC also runs in userspace too. So does HTTP. So does WebSocket. Every protocol above the kernel is userspace. QUIC being in userspace is no different." That sounds convincing. It is also wrong. But the reason it's wrong is not obvious unless you trace the actual packet flow for both approaches.
Comparing QUIC to TCP for inter-node communication is not a matter of trade-offs. It is a category error. QUIC was designed for a specific environment that looks nothing like the inside of a cluster.
Understanding the protocol layers
This is where most of the confusion comes from, and where the conversation usually goes sideways. People treat TCP and QUIC as direct alternatives. Swap one for the other. But they sit differently in the protocol stack, and that difference is the entire point.
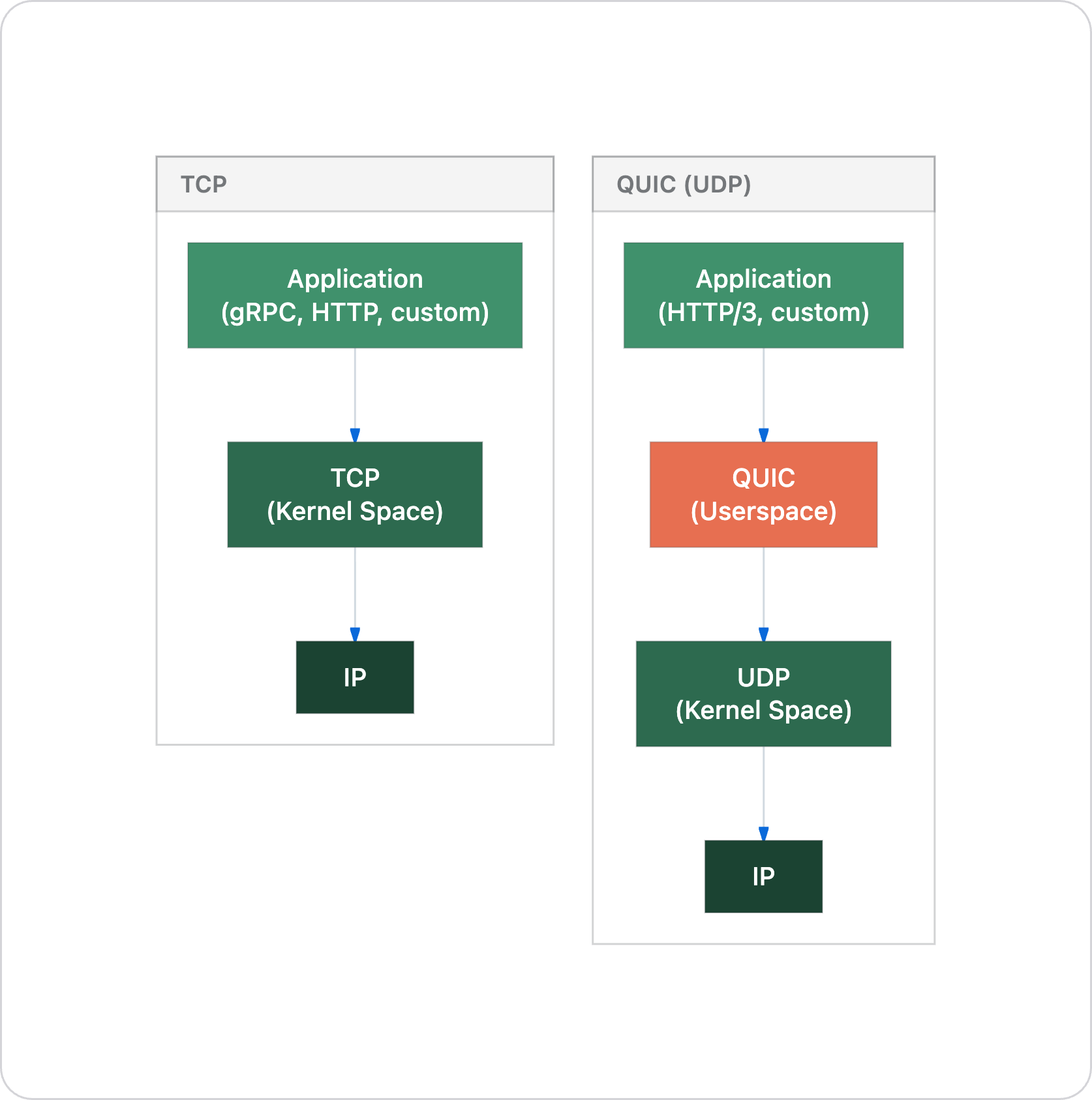
TCP is a transport protocol that lives in the kernel. UDP is a transport protocol that lives in the kernel. They are peers.
QUIC is also a transport protocol but it does not live in the kernel. It lives in userspace and uses UDP underneath as a tunneling layer. UDP is there because it's the simplest way to get packets through internet middleboxes, NATs, and firewalls that would otherwise drop unknown protocol numbers.
So when someone says "let's use QUIC instead of TCP," what they are actually proposing is: let's use UDP as a dumb packet pipe, and rebuild all of TCP's guarantees (reliability, ordering, congestion control, flow control) in our application process. Then add mandatory encryption on top.
That is not a minor architectural detail. That is the entire discussion.
The environment matters more than the protocol
QUIC was born at Google. Not for cluster communication. For the internet. Specifically, for Chrome talking to Google's edge servers across unpredictable network paths, through NATs, over connections that break when your phone switches from WiFi to cellular.
Every design decision in QUIC traces back to internet-scale problems:
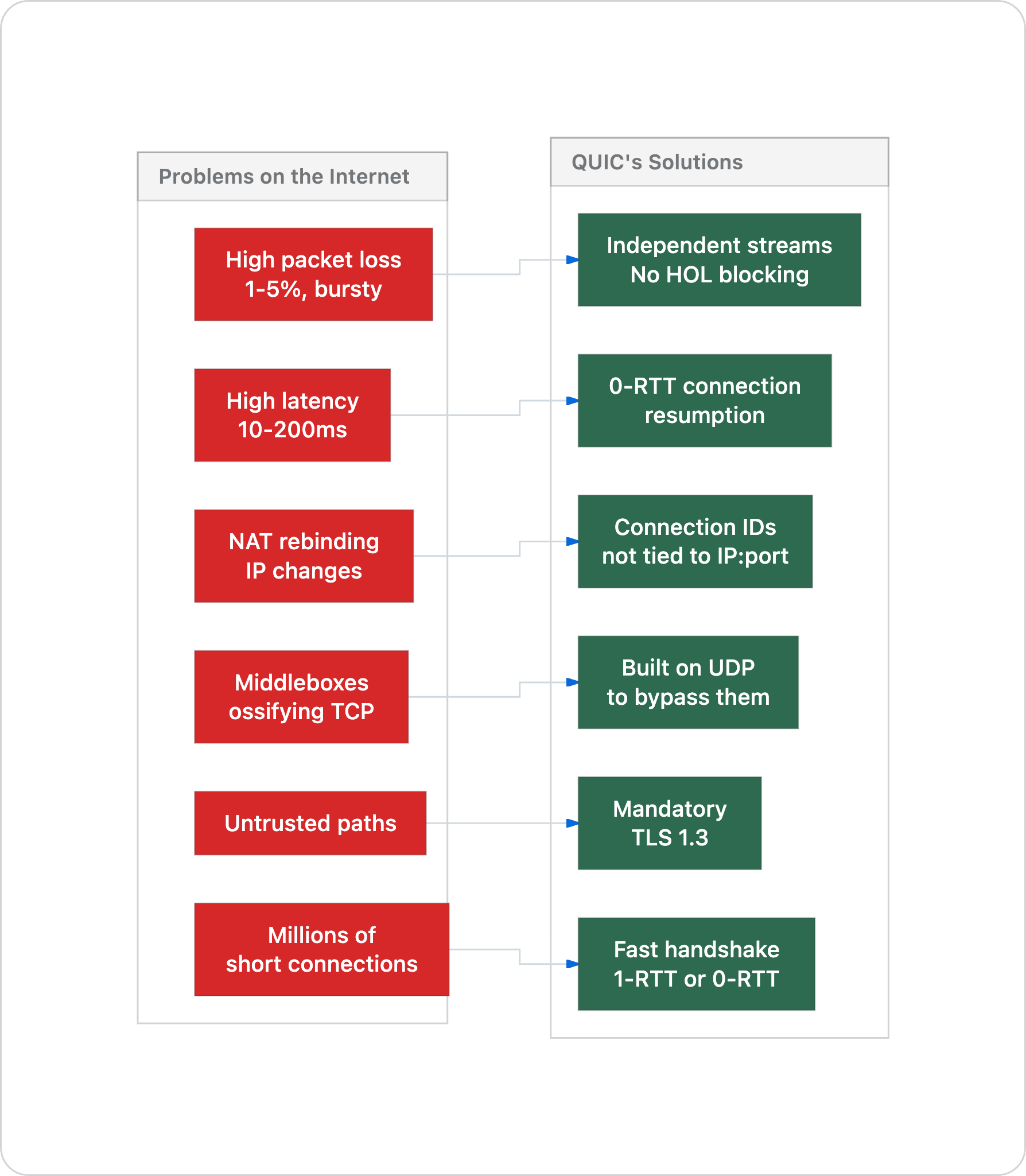
Now look at a private network. None of these problems exist:
Property in a private LAN Reality
────────────────────────────── ──────────────────────────────
Packet loss < 0.001% (basically zero)
Latency < 0.1ms (sub-microsecond with RDMA)
IP changes mid-connection Never happens
Middleboxes None. You own the network.
Trust model Trusted, or mTLS if needed
Connection count Tens. Maybe low hundreds.
Connection lifetime Hours, days, weeks
Every problem QUIC was designed to solve does not exist inside a private LAN network. You are paying for solutions to problems you do not have.
Where the work actually happens
The common rebuttal — "gRPC is in userspace too, so QUIC being userspace doesn't matter" — falls apart once you trace what actually happens when data moves from your application to the wire. Not the conceptual model. The actual execution path.
Here is the fundamental difference:

With TCP, the application does almost nothing. The kernel and NIC hardware handle the heavy lifting. With QUIC, the application process does all the transport work itself.
Path 1: gRPC over TCP
Your application serializes a protobuf message. Let's say it's 64KB. A chunk of data destined for another node.
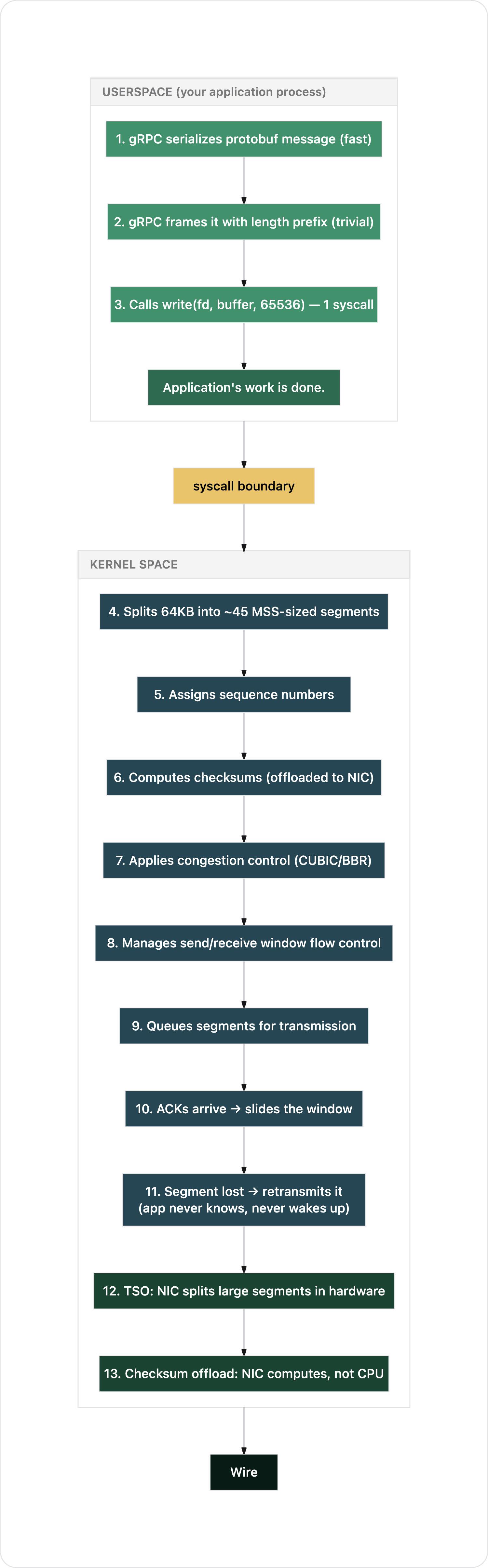
Count the syscalls your application made: one. A single write(). Everything else happened in the kernel and NIC hardware. Your process didn't wake up again until it had more data to send.
Path 2: Application protocol over QUIC over UDP
Same scenario. 64KB of data. But now over QUIC.
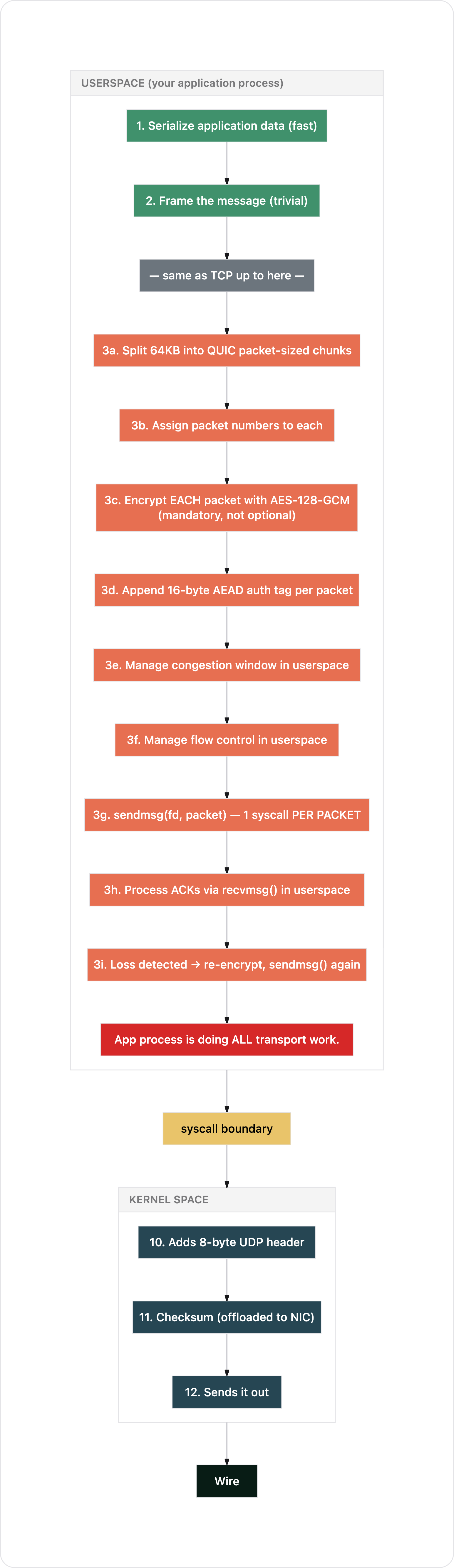
Count what happened in your application process: segmentation, packet numbering, encryption (per packet), congestion control, flow control, loss detection, retransmission. All of it. Plus roughly 45 syscalls instead of 1 (or ~3-4 with aggressive GSO batching, but still more).
Now look at both paths side by side and ask: where is "the work?"
With TCP, 90% of the transport work happens in the kernel and NIC hardware. With QUIC, 90% of the transport work happens in your application process.
gRPC and HTTP being in userspace is the small box at the top: serialization and framing. QUIC being in userspace is the entire middle section: the actual transport layer. The people saying "gRPC/HTTP/WS is userspace too" are pointing at the small box and saying "see, same thing." It is not the same thing.
The kernel optimizations that QUIC structurally cannot use
This is not about TCP being "more mature." These are architectural advantages that come from the transport layer living in kernel space with direct access to hardware.
TCP Segmentation Offload (TSO)
When your application writes 64KB to a TCP socket, the kernel does not split it into 45 packets using CPU time. It constructs a large segment descriptor and hands it to the NIC. The NIC hardware splits it into MTU-sized packets right before putting them on the wire.
Your CPU does almost nothing for this. The NIC is doing the segmentation.
QUIC cannot use TSO. Each QUIC packet must be individually encrypted in userspace before it crosses the syscall boundary. You cannot hand the NIC a 64KB encrypted blob and say "split this into packets." The encryption is per-packet, so the splitting must happen before encryption, which must happen in userspace.
Generic Receive Offload (GRO)
On the receive side, the NIC and kernel coalesce multiple incoming TCP segments into large buffers. Your application calls recv() once and gets 64KB+ of data that physically arrived as dozens of packets.
With QUIC, the kernel cannot coalesce incoming UDP datagrams because it cannot see inside the encrypted QUIC packets. Each one must be individually delivered to userspace, individually decrypted, and individually reassembled by the QUIC library.
Zero-copy I/O with sendfile()
This is the critical one for any data-intensive system. TCP supports sendfile() and splice(), which move data directly from the filesystem page cache to the NIC without ever copying it into userspace memory.
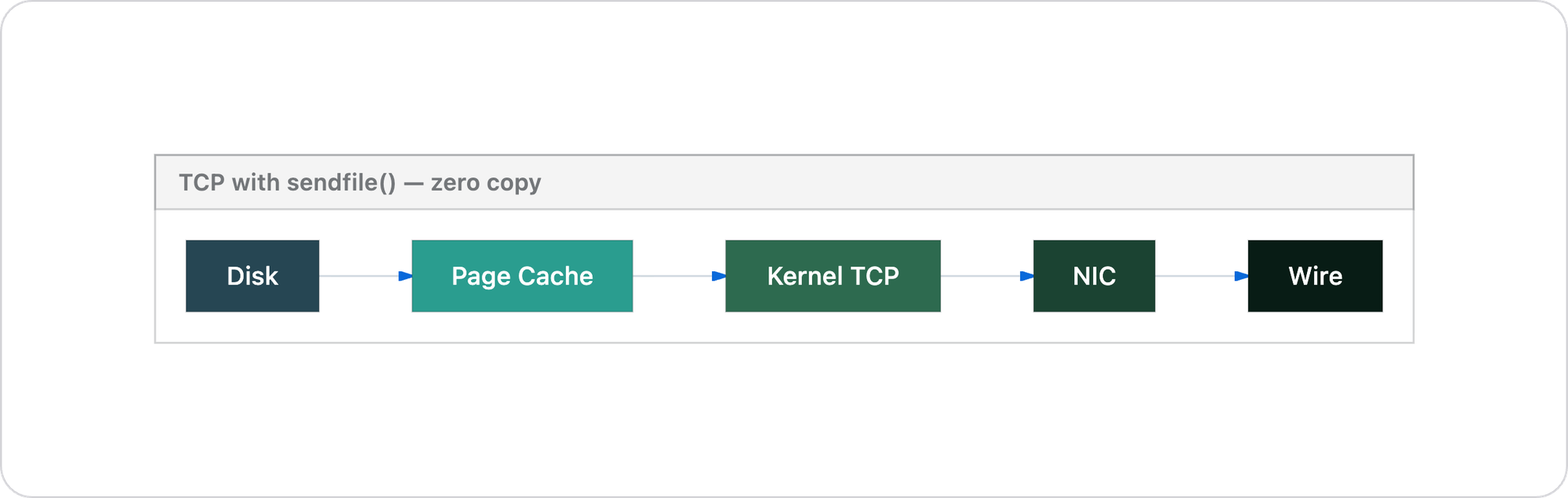
Data never enters userspace. Zero copies, zero context switches for the data path.
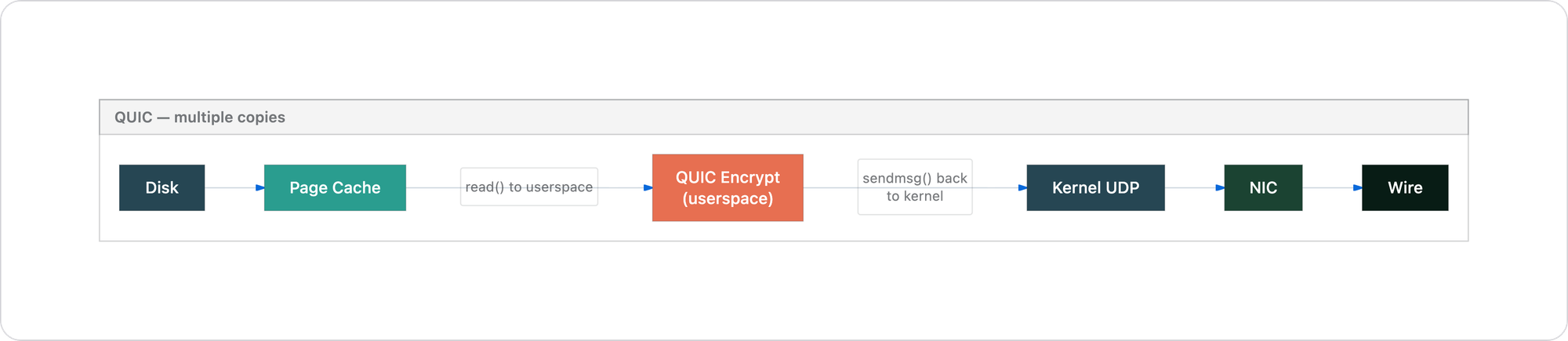
Two extra copies, two extra context switches. For any distributed system moving large volumes of data between nodes, this is not a small difference. It is the difference between the data touching userspace memory zero times versus two or more times per operation. Each copy burns memory bandwidth. Each context switch burns CPU cycles.
Apache Kafka famously depends on sendfile() for its performance, transferring log segments directly from disk to network without ever reading them into the application process. This optimization is structurally impossible with QUIC.
Kernel TLS (kTLS)
If you need encryption between cluster nodes for compliance or zero-trust requirements, Linux supports kernel TLS. The TLS record layer executes in kernel space, preserving the zero-copy path:
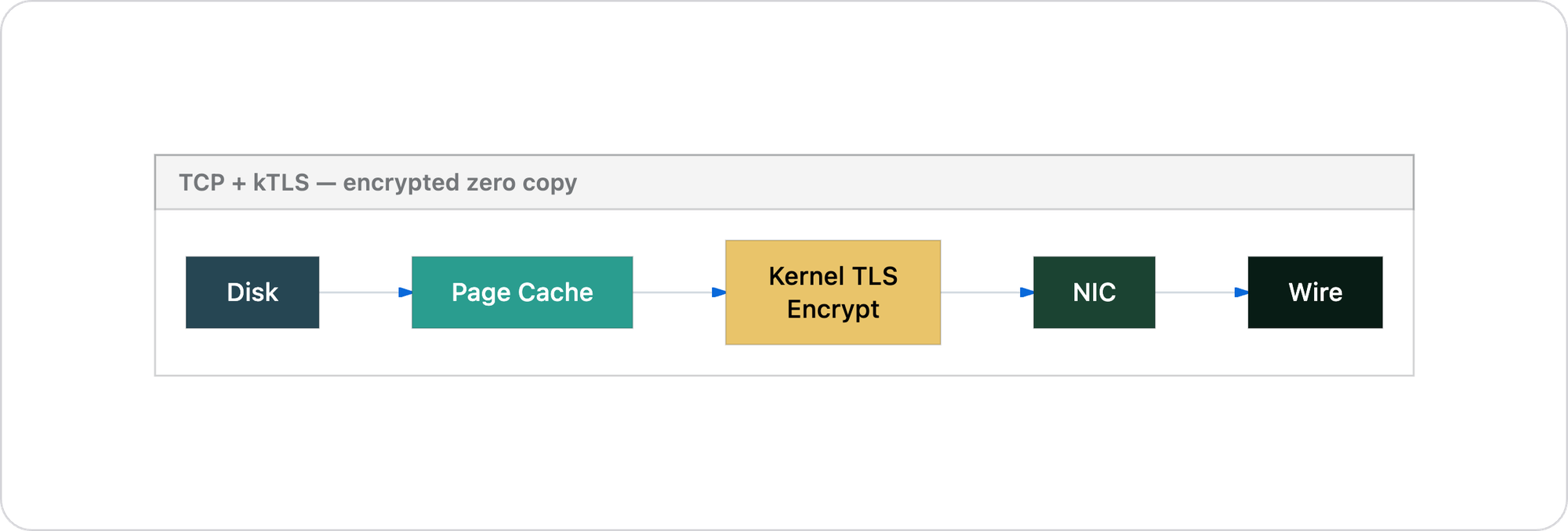
You get encryption without giving up any of TCP's performance advantages. QUIC's mandatory per-packet encryption in userspace cannot match this.
Packet-level breakdown
Let's look at exactly what goes on the wire.
TCP packet (no encryption)

┌─────────────────────────────────────────────────┐
│ IPv4 Header │ 20 bytes │
├─────────────────────────────────┼───────────────┤
│ TCP Header │ 20 bytes │
├─────────────────────────────────┼───────────────┤
│ Payload │ up to 1460 │
│ (your actual data) │ bytes │
└─────────────────────────────────┴───────────────┘
Total overhead: 40 bytes per packet
Payload efficiency: 1460 / 1500 = 97.3%
CPU cost per packet: near zero (checksums offloaded to NIC)
QUIC packet (short header, post-handshake)
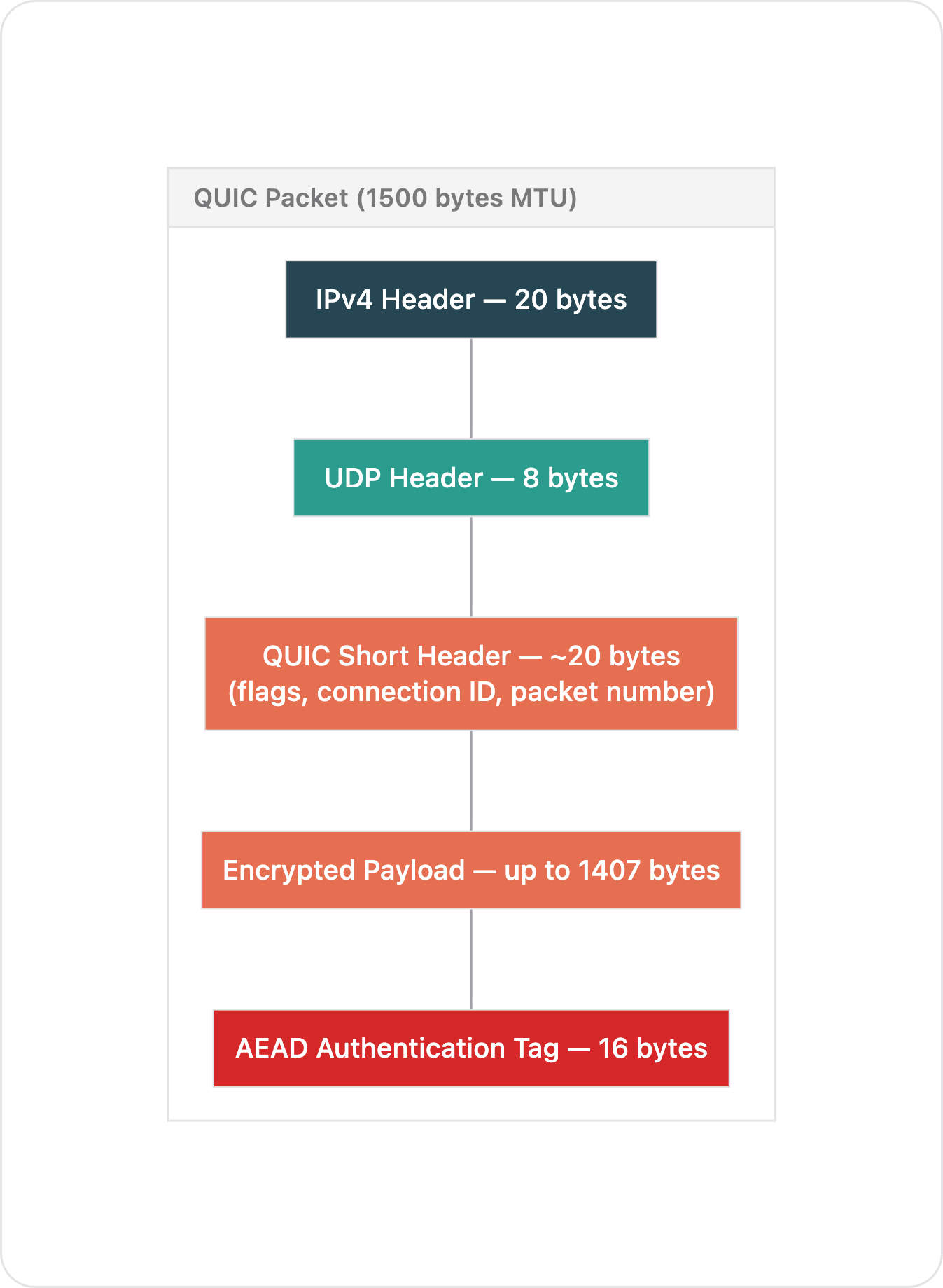
┌─────────────────────────────────────────────────┐
│ IPv4 Header │ 20 bytes │
├─────────────────────────────────┼───────────────┤
│ UDP Header │ 8 bytes │
├─────────────────────────────────┼───────────────┤
│ QUIC Short Header │ ~20 bytes │
│ (flags, connection ID, │ │
│ packet number, encrypted) │ │
├─────────────────────────────────┼───────────────┤
│ Encrypted Payload │ up to 1407 │
│ (your data, encrypted) │ bytes │
├─────────────────────────────────┼───────────────┤
│ AEAD Authentication Tag │ 16 bytes │
└─────────────────────────────────┴───────────────┘
Total overhead: 64 bytes per packet
Payload efficiency: 1407 / 1500 = 93.8%
CPU cost per packet: one AES-128-GCM encrypt/decrypt (userspace)
24 extra bytes of overhead per packet, plus a cryptographic operation for every single packet. Let's see what that means at scale.
Cost at scale

At 10 Gbps inter-node throughput, 1500-byte MTU:
TCP QUIC
──────────────────────────────────────────────────────────
Packets per second ~833,000 ~833,000
Header overhead/sec 33.3 MB/s 53.3 MB/s
Wasted bandwidth ── ~20 MB/s extra
Syscalls/sec ~1 per write() ~55,000 (with GSO)
(kernel batches) up to 833,000 (without)
Crypto operations/sec 0 ~833,000
Context switches/sec minimal ~55,000+
At 10 Gbps, QUIC adds ~55,000 context switches per second and 833,000 cryptographic operations that TCP avoids entirely.
With jumbo frames (9000-byte MTU, standard in clusters):
TCP QUIC
──────────────────────────────────────────────────────────
Packets per second ~139,000 ~139,000
Crypto operations/sec 0 ~139,000
Syscalls/sec ~1 per write() ~10,000 (with GSO)
Jumbo frames reduce the packet rate for both, but QUIC still pays per-packet encryption cost. TCP's cost is essentially constant because the NIC handles segmentation regardless of MTU.
What production systems actually chose
This is not a theoretical argument. Every major distributed system in production uses TCP for internal node-to-node communication. Not one uses QUIC.
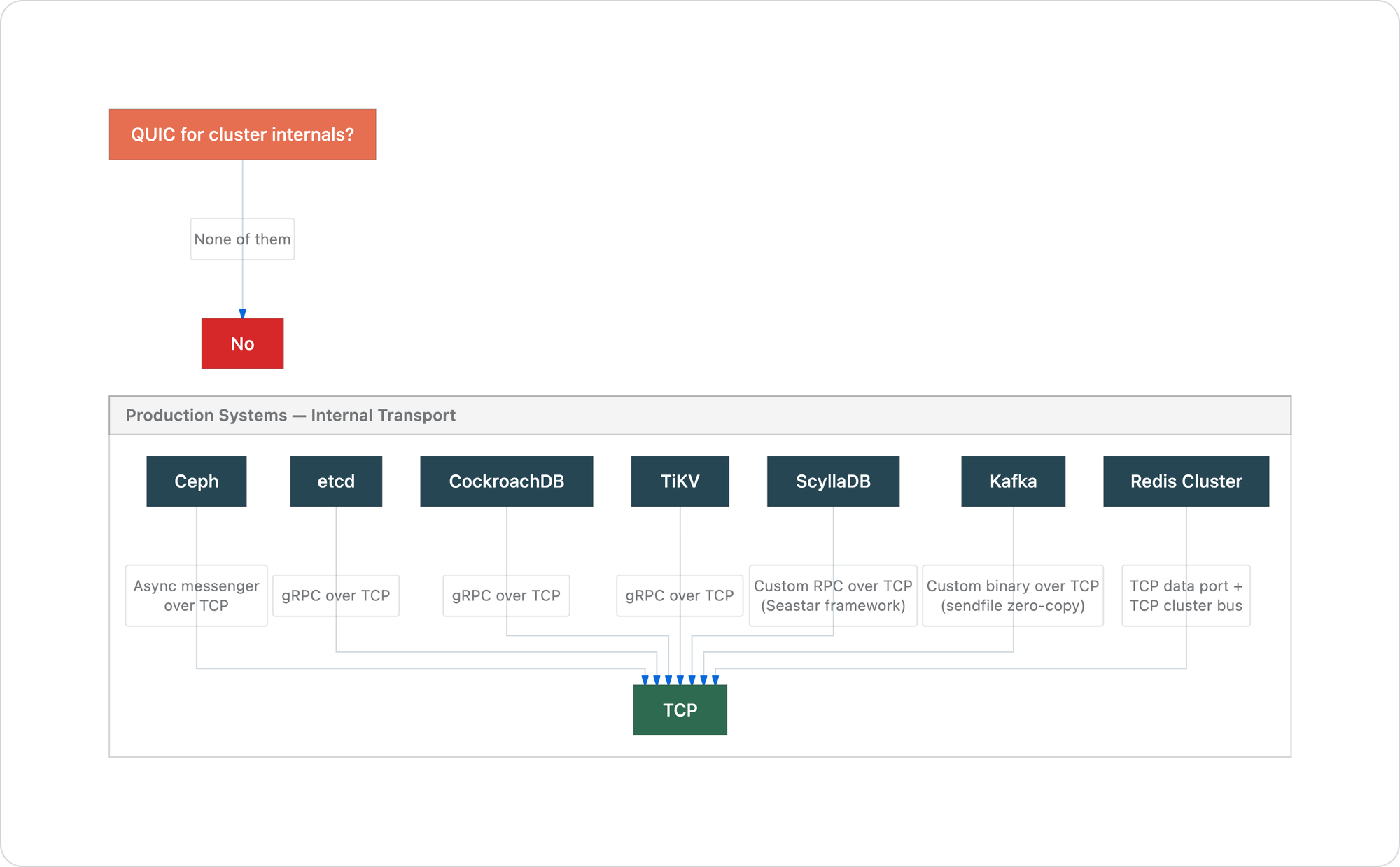
etcd uses gRPC over TCP for Raft consensus and peer communication. The entire consistency model of Kubernetes depends on etcd's Raft log replication, which relies on TCP's reliable ordered delivery at the kernel level.
CockroachDB uses gRPC over TCP for all inter-node RPC. Distributed SQL execution, Raft replication, leaseholder coordination. Heavy cross-node traffic, all on TCP.
ScyllaDB uses a custom RPC protocol over raw TCP sockets through the Seastar framework. Each CPU core gets its own TCP connections in a shared-nothing architecture. When they needed to go faster than kernel TCP, they went toward DPDK (kernel bypass with a custom userspace TCP stack), not toward QUIC. They kept TCP semantics and eliminated the kernel. QUIC goes the other direction: keeps the kernel in the path via UDP while moving the expensive transport work to userspace.
Apache Kafka uses a custom binary protocol over TCP. Its throughput depends on the zero-copy sendfile() path described earlier — structurally impossible with QUIC.
Redis Cluster uses TCP for both the data port and the cluster bus (a gossip protocol on port+10000 for failure detection and configuration).
Ceph supports two messenger implementations, both TCP-based: the simple messenger and the async (epoll-based) messenger. RADOS replication and recovery, which involves massive data movement during rebalancing, runs entirely over TCP.
TiKV (the storage engine behind TiDB) uses gRPC over TCP for Raft communication and data transfer between nodes.
The pattern is not a coincidence. These systems were built by teams who deeply understand transport layer performance. They all arrived at the same answer.
When QUIC genuinely makes sense
QUIC is a well-engineered protocol. The goal of this article is not to dismiss it — it is to be precise about where it belongs.
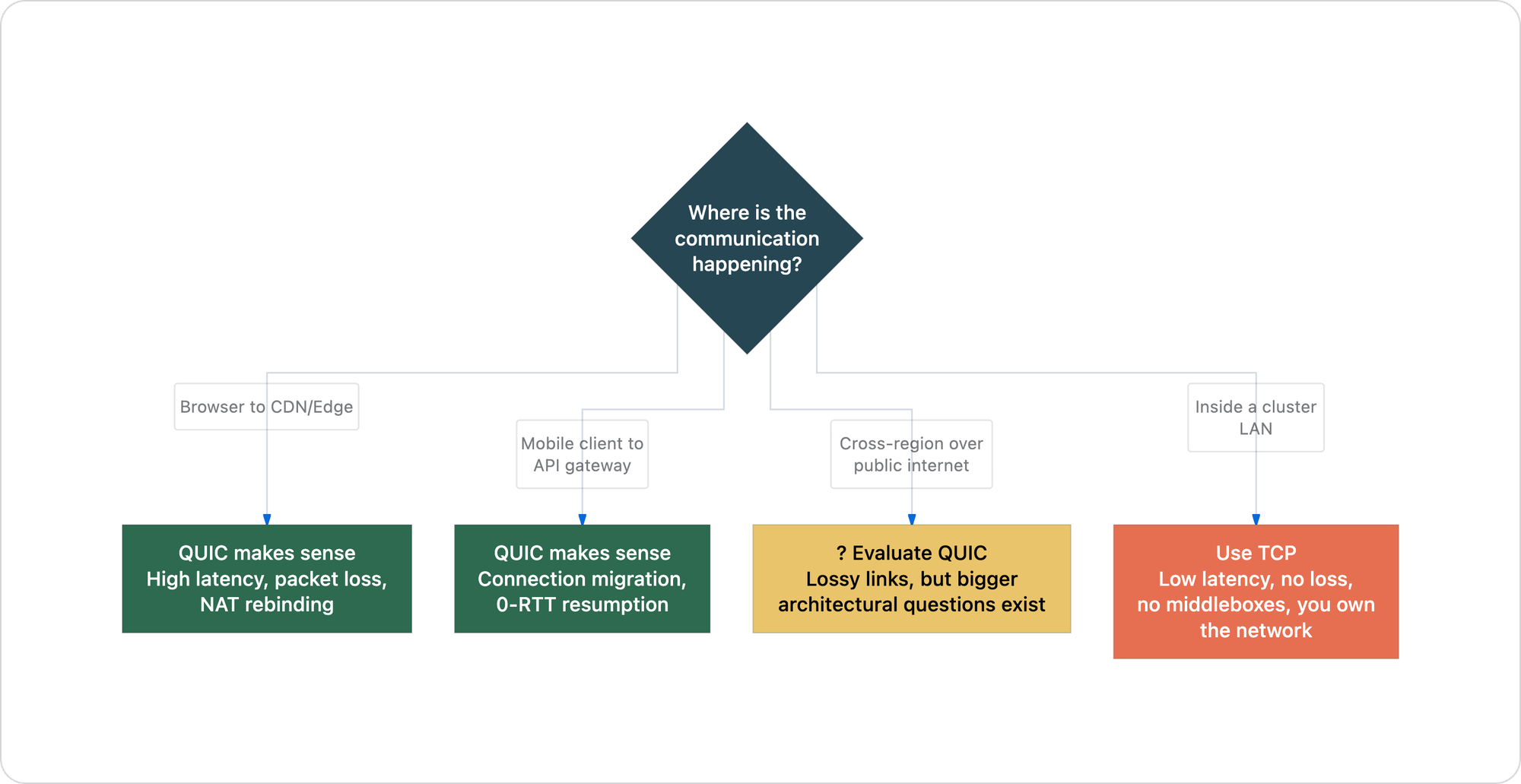
Browser-to-CDN, mobile clients, multiplexed streams over lossy links, and cross-region traffic over public internet — these are the environments QUIC was built for. Inside a cluster LAN with sub-millisecond latency and near-zero packet loss, none of these conditions exist.
The right architecture for cluster internals
For a multi-node cluster, the transport choice is straightforward:
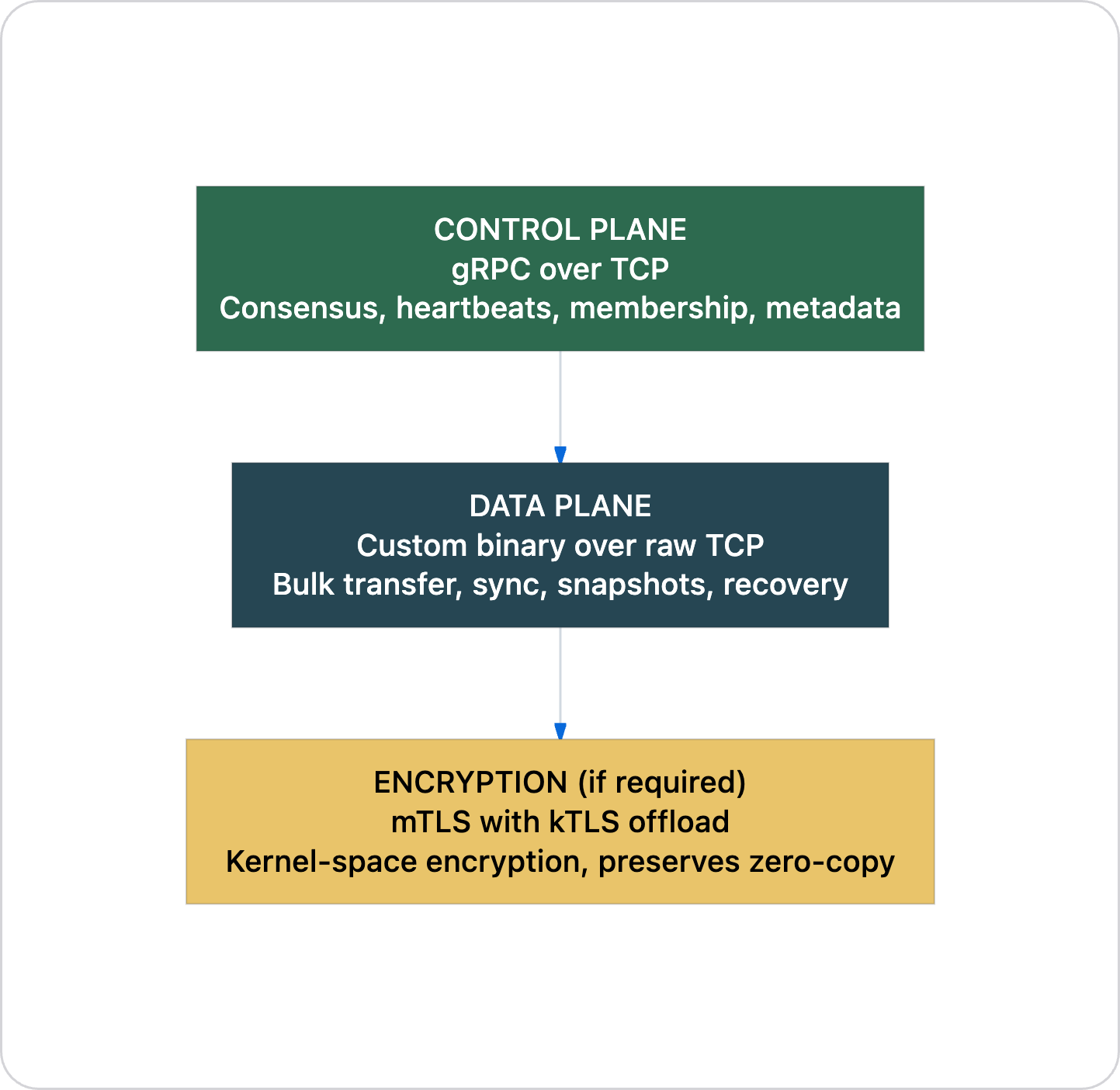
And if you ever need to go faster than kernel TCP, the direction is not QUIC. The direction is:
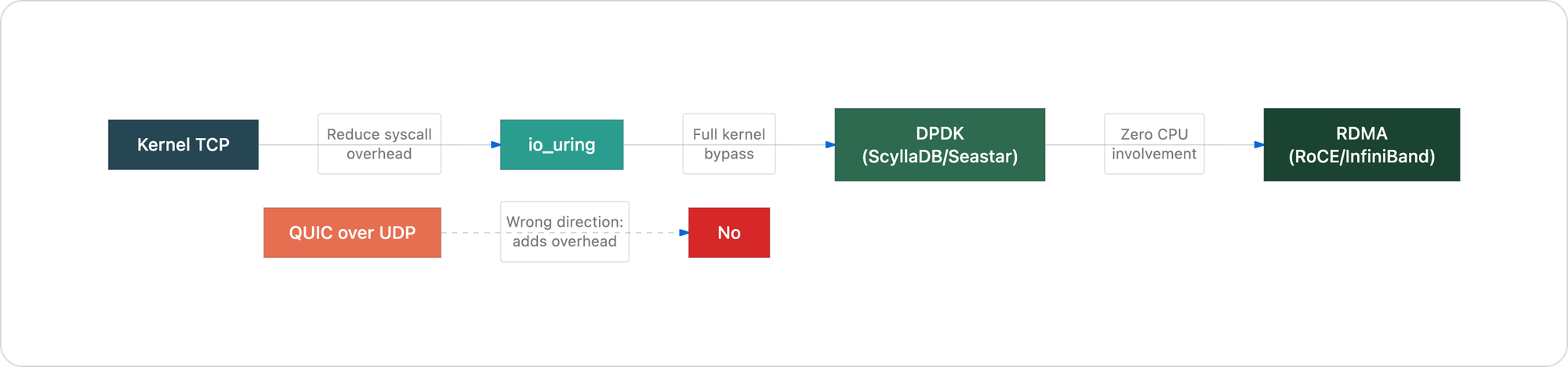
All three of these either keep TCP or go below it. None of them add a layer on top of UDP and call it progress.
TCP, inside a cluster, is not just the better option. It is the only option that makes engineering sense. The kernel handles your transport. The NIC accelerates it in hardware. Your application process stays free to do application work. Thirty years of optimization, hardware offload, and zero-copy I/O support this path. Inside a cluster network where you control every switch, every cable, every MTU setting, QUIC's trade-offs buy you nothing and cost you everything.