
How Does Your Database Store Millions of Records?
Every database write faces the same challenge: disks are 1,000x slower than memory. Your choice between B-Trees and LSM Trees can make your database 10x faster or 10x slower. Here's how they actually work and when to use each.

Every time you save a photo, complete a purchase, or send a message, your data travels from application code to permanent storage. But how does this actually work at the physical level?
During my years working with production systems, I've seen teams choose the wrong storage engine and suffer 10x performance penalties. The difference between B-Trees and LSM Trees isn't academic, it's the reason Discord's migration to Cassandra made their writes 10x faster, and why Netflix uses different approaches for viewing history versus recommendations.
The Fundamental Problem: Disk is Slow
Before getting into data structures, understand the constraint we're solving for.
In-memory storage is fast but expensive and volatile & power off, data gone. Disk storage (SSDs or HDDs) is cheap and persistent, but dramatically slower:
- RAM: ~100 nanoseconds
- SSD: ~100 microseconds (1,000x slower)
- HDD: ~10 milliseconds (100,000x slower)
This performance gap shapes everything. You can't just dump a hash table to disk and expect decent performance.
Here's the insight: disks hate random access but excel at sequential access. Reading 1 byte at a random location is slow. Reading 1MB of consecutive bytes is much faster per byte.
Database storage engines exist to minimize random disk access. This leads us to two fundamentally different approaches.
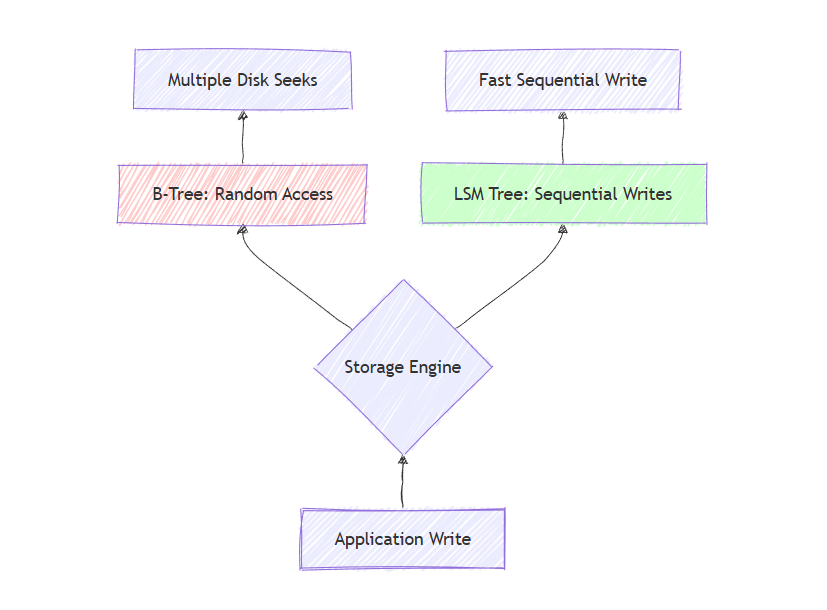
B-Trees: The Read-Optimized Classic
PostgreSQL, MySQL, and SQLite all use B-Trees by default. They've been around since the 1970s for good reason.
How B-Trees Work?
Think of a B-Tree as a sorted, balanced tree structure. The root node acts as an index, directing you left or right. Each level narrows your search until you reach a leaf node containing your data.
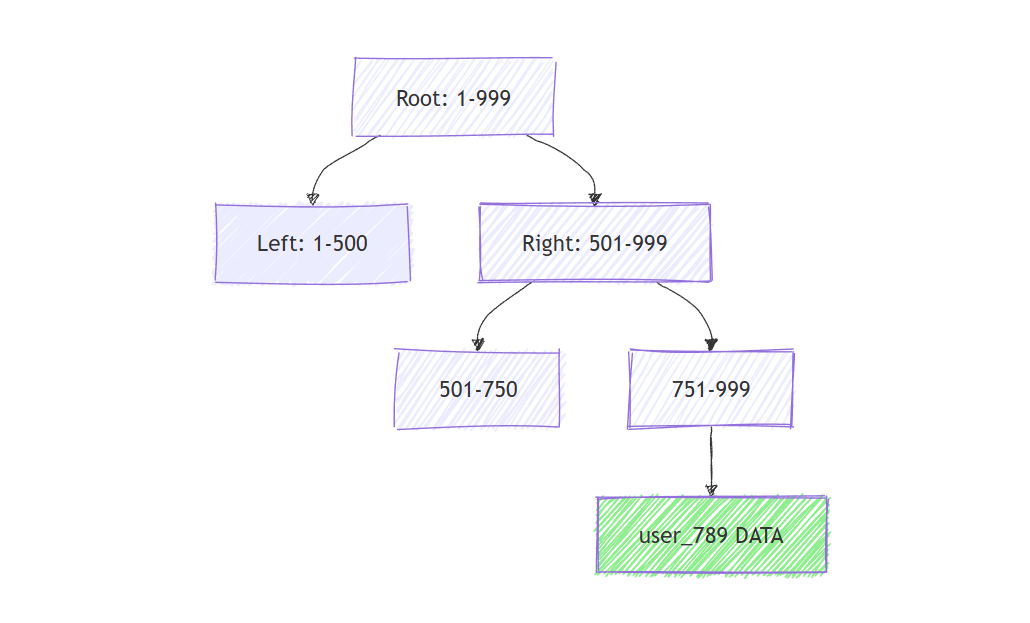
Looking up user_789:
- Read root node: "keys 501-999 go right"
- Read right child: "keys 751-999 go right"
- Read that node: find
user_789
That's typically 3-4 disk reads for any lookup, guaranteed by the balanced tree structure.
B-Tree Strengths
Point lookups are fast. Need a specific user? 3-4 disk reads.
Range queries are efficient. "Give me users 100-200" works well because data is sorted and stored contiguously.
This makes B-Trees perfect for OLTP (Online Transaction Processing) systems with frequent random reads, think bank accounts, e-commerce orders, user profiles.
B-Tree Weaknesses
Writes are expensive. To insert data:
- Read multiple nodes to find the insertion point
- Split nodes if full
- Update parent pointers
- Potentially rebalance the tree
One write can trigger dozens of disk operations. If your disk is nearly full and you're doing random inserts, you're constantly seeking different locations is painful for HDDs, inefficient even for SSDs.
B-Trees optimize for reads at the cost of writes.
LSM Trees: The Write-Optimized Modern Approach
LSM (Log-Structured Merge) Trees power Cassandra, RocksDB, LevelDB, and most NoSQL databases handling high write volumes.
The philosophy is radically different: instead of maintaining sorted organization on disk, write things down as they arrive just like a journal.
How LSM Trees Work?
When a write arrives:
- Write to MemTable (in-memory sorted buffer)
- When MemTable fills (~64MB), flush to disk as an immutable SSTable (Sorted String Table)
- Write sequentially in one operation
Sequential writes are fast: 100-500 MB/s even on HDDs, compared to 1-2 MB/s for random writes.
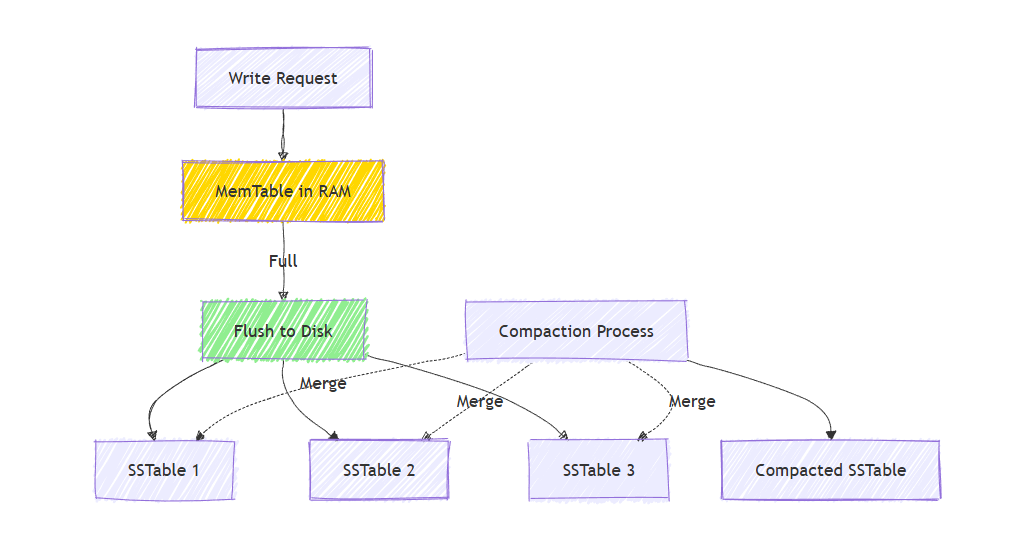
The Read Trade-off
To read user_789:
- Check current MemTable
- Check most recent SSTable
- Check next SSTable
- Continue until found
Unlike B-Trees, data isn't in one organized tree, it's across multiple sorted files.
How LSM Trees Stay Fast
Bloom Filters: Before checking each SSTable, ask: "Does this file contain user_789?" If no, skip entirely. This avoids unnecessary disk reads.
Compaction: Background process merges SSTables, removes deleted data, combines duplicates. Data ages through levels (hence "leveled compaction").
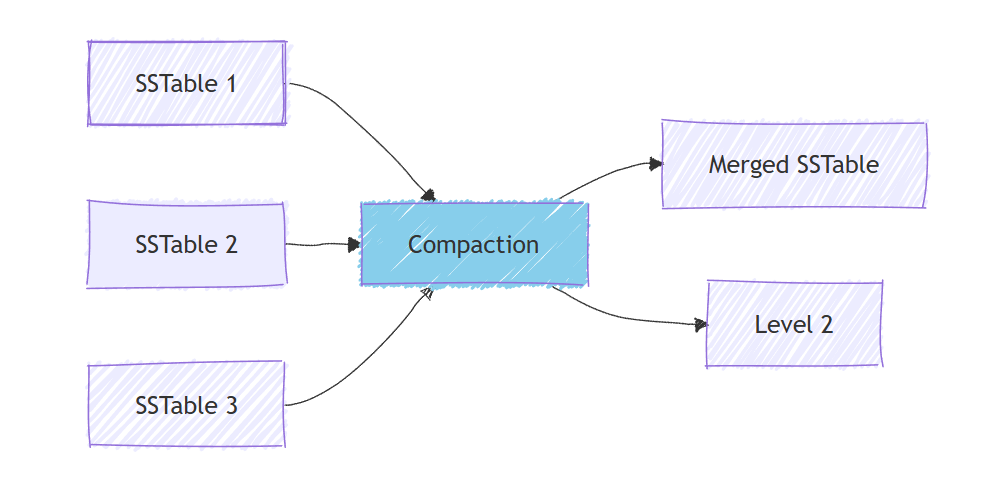
Result: Writes stay fast (always sequential), reads are slower than B-Trees for point lookups but manageable with Bloom filters and caching.
LSM Trees handle millions of writes per second because you're appending to memory and occasionally flushing to disk.
When to Use Each Approach
Use B-Trees When You Have:
- Read-heavy workloads (80:20 read-to-write ratio)
- Need for fast point lookups and range scans
- Transactional workloads (bank accounts, orders)
- Data fitting in memory or fast SSDs available
Examples: PostgreSQL for user accounts, MySQL for product catalogs, SQLite for mobile app databases
Use LSM Trees When You Have:
- Write-heavy workloads (tons of inserts/updates)
- Acceptable slightly slower reads
- Time-series data (logs, metrics, sensors)
- Need to ingest massive data volumes quickly
Examples: Cassandra for Netflix's viewing history (300M writes/day), RocksDB for Facebook messaging, InfluxDB for monitoring metrics
Example: Discord's Migration
Discord initially used MongoDB (B-Trees) for message storage. Worked fine initially, but at scale with billions of messages:
- Reads were acceptable
- Writes became a bottleneck
- Random B-Tree inserts caused disk fragmentation
- Insert performance degraded
They migrated to Cassandra (LSM Trees):
- Writes became 10x faster
- Now handle millions of messages per second
- Sequential write pattern eliminated fragmentation
The Actual Reality
Modern databases often blend approaches:
- RocksDB: LSM Trees with read optimizations
- PostgreSQL: B-Trees + WAL (Write-Ahead Log, append-only)
The best choice depends on your access patterns. In my experience running production systems, I've learned:
- Start with B-Trees (PostgreSQL/MySQL) for general-purpose applications
- Switch to LSM Trees when write volume becomes the bottleneck
- Monitor disk I/O patterns if they'll tell you when you've chosen wrong
Quick Takeaways
- Disks are 1,000-100,000x slower than RAM this constraint shapes everything
- B-Trees optimize for reads with logarithmic lookup but expensive writes
- LSM Trees optimize for writes with sequential I/O but trade-off read performance
- Real-world systems often use hybrid approaches
- Your access pattern determines the right choice not theoretical performance
The storage engine matters more than most developers realize.